This post summarizes work published in SoCC ‘16, ReStream: Accelerating Backtesting and Stream Replay with Serial-Equivalent Parallel Processing (also here).
When real-time isn’t fast enough
When building real-time data-driven applications developers are continually challenged by a seemingly simple question, “what will the new software do when we deploy it?” This is a challenge I encountered several times while building the if(we) social networks. When deploying a new anti-spam rule, for example, one wants to know how it performs given the logs of the past 30 days as input, but one does not want to wait for 30 days to have an answer. An hour-long replay job might be acceptable, but results in a few minutes would be much better.
Similar needs for backtesting can be found just about anywhere people are developing real-time applications. I found it essential when creating real-time personalized recommendations; it was key to enabling an Agile practice in machine learning and data science. It is a routine procedure in finance, and the need for it abounds in other areas including security, advertising, e-commerce, and emergent applications such as IoT.
For developers doing backtesting, real-time replay is much too slow. A speedup of 1,000x is commonly desired, and even 10,000x can seem reasonable to ask for. ReStream is a proof-of-concept system that shows how accelerated replay can be achieved.
What won’t work
The traditional goal of stream processing systems has been low latency, minimizing the delay between the arrival of an event and the system’s response to it. Backtesting and replay demand high-throughput, which minimizes overall job completion time across millions or billions of sequential events. For workloads that partition naturally it can be simple to scale out a streaming system to achieve accelerated replay, but for many workloads no such partitioning exists.
There are many mature industrial-strength parallel database systems, so we could imagine partitioning our input logs among a number of clients, each of which submits a stream of transactions. However, the consistency and isolation guarantees provided by the database do not ensure proper sequencing of events. At 1,000x acceleration events processed in one second could have occurred more than 15 minutes apart. Close synchronization among clients can help, but unless we also control the commit order of concurrent transactions the outcome of accelerated replay could be quite different from that of real-time processing.
Serial-equivalent parallel processing
What is needed for full-fidelity accelerated replay is “serial-equivalence.” Suppose we are given a program that consumes input from a log, sometimes producing output and sometimes updating its internal state as it goes along. We want to achieve an identical output from a number of parallel programs, possibly communicating with one another, each consuming a partitioned portion of our original input log and producing outputs along with corresponding log sequence numbers.
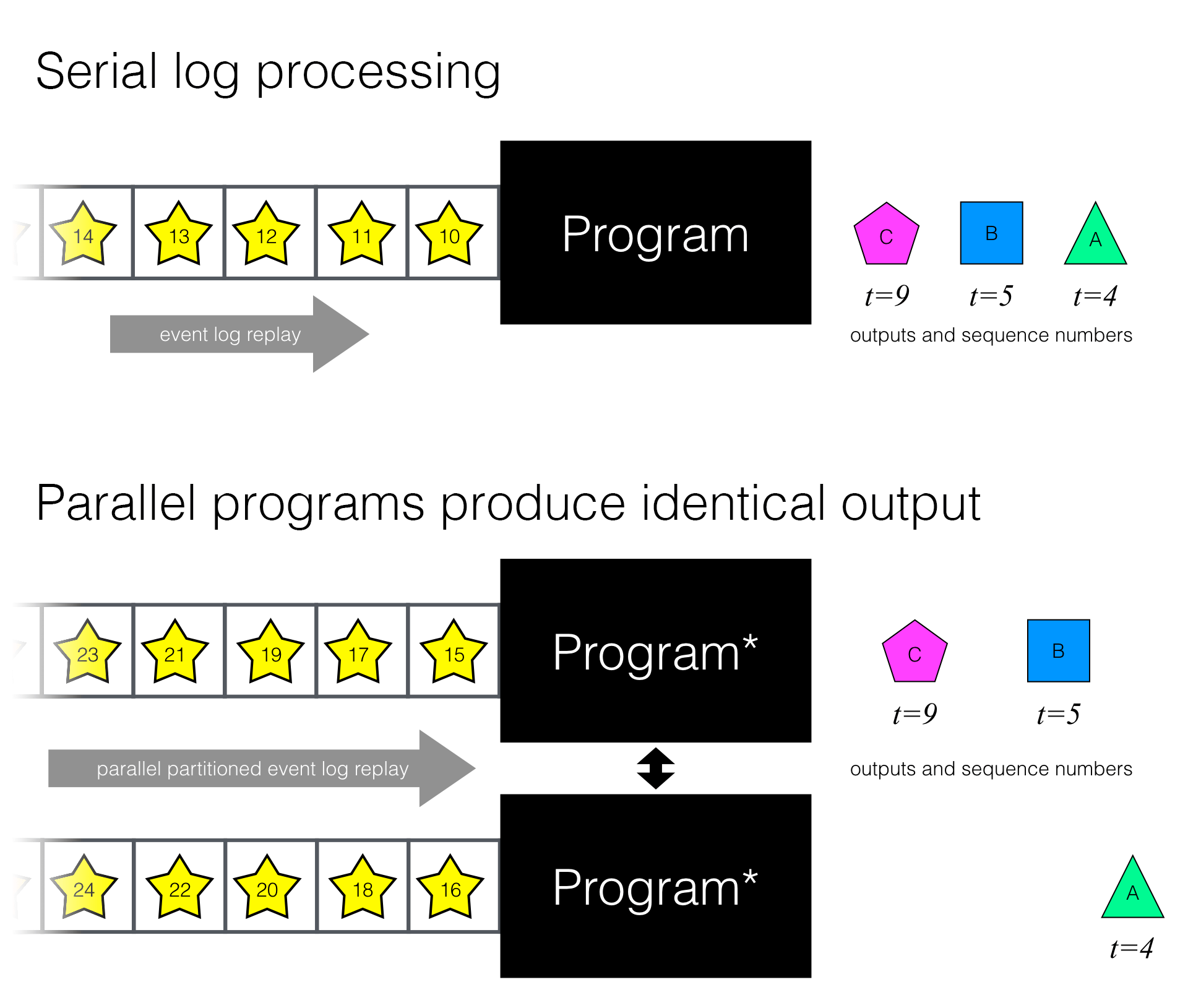
Serial-equivalent parallel processing is what developers attempting accelerated replay of real-time applications need.
ReStream and Multi-Versioned Parallel Streaming
Achieving serial-equivalent parallel processing relies on a key observation: causal dependencies between processing of log records are often sparse. For example, messaging activity on a social network generally exhibits geographic clustering, so we can imagine an anti-spam system analyzing communication patterns within regions in parallel, coordinating across them when necessary. The Multi-Versioned Parallel Streaming (MVPS) provides the sort of loose coupling that allows computations to proceed with parallelism, enforcing order when necessary, but not necessarily otherwise.
A multi-versioned state store is a key building block for MVPS. It presents an API of a key-value store, with the further requirement that all reads and write operations must be accompanied by a timestamp. Reads into the past are allowed, with the multi-versioned state returning the value of the write with the timestamp that most closely precedes the read timestamp. Writes to the future are also allowed, but writing into the past is not; writing to a key at a timestamp less than the greatest read timestamp serviced at that key is an error.
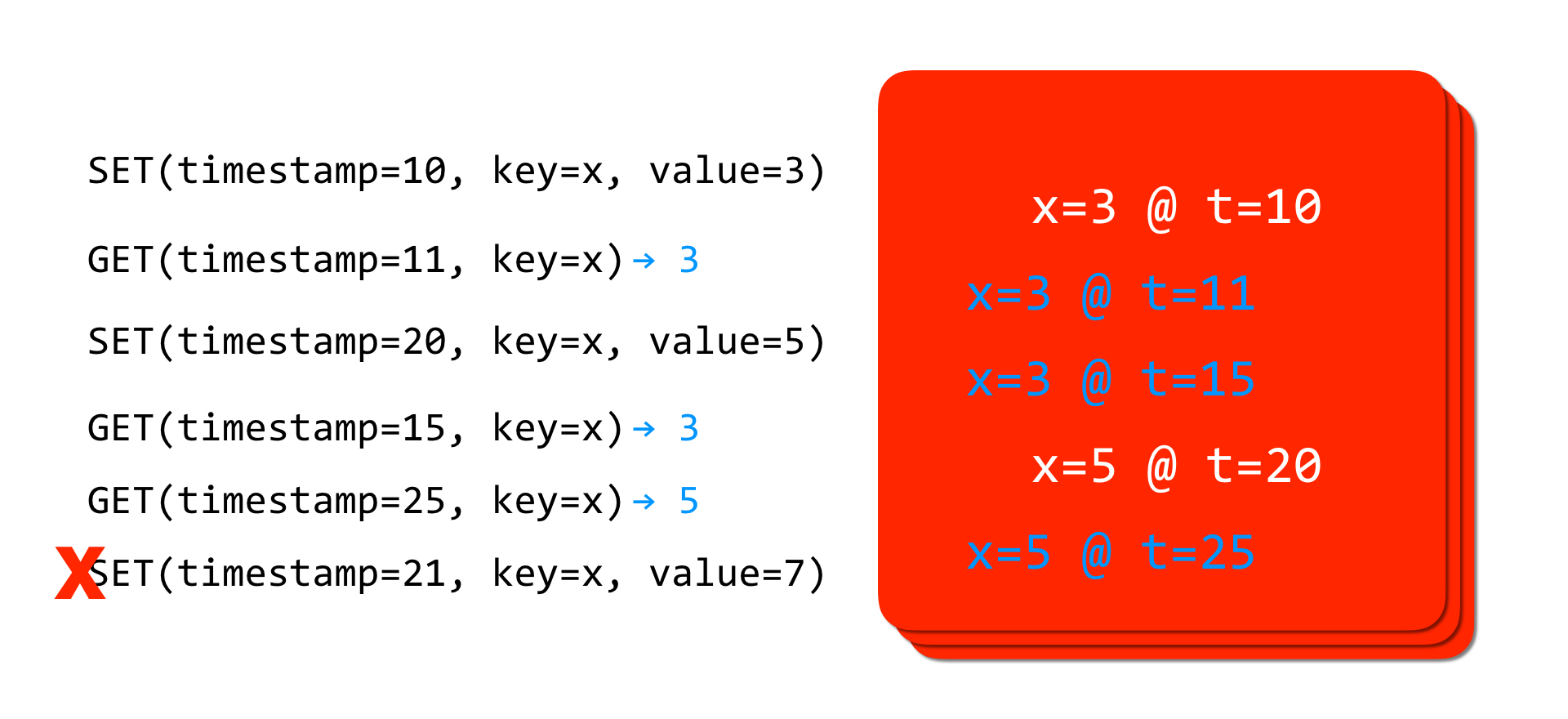
MVPS combines multi-versioned state with program analysis and a runtime that ensures that writes always precede reads at a given key. The example that follows serves to illustrate how it does this.
Anti-spam example
As a simple example, consider a multi-part rule for a social network anti-spam system. We flag a message as possible spam when two conditions hold: 1) the sender has been sending to non-friends more than to friends by a factor of 2:1, and 2) the message originates from an IP address for which more than 20% of messages sent have contained an e-mail address.
The following code shows a reactive program implementing this algorithm using a simplified Scala syntax:

ReStream performs static analysis on the program to obtain a graph of potential dependencies between reactive event handlers, mapping out the multi-versioned state variables that might be written to or read from by each. Commonly these form a Directed Acyclic Graph (DAG), a key requirement that enables accelerated replay.
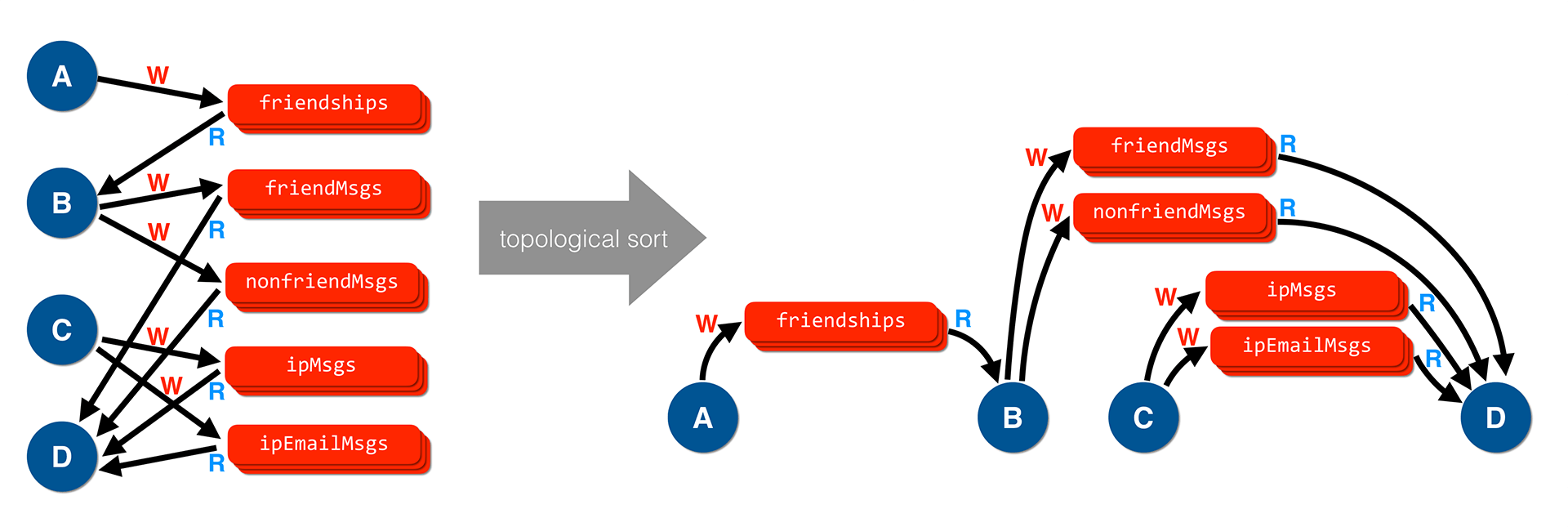
A topological sort reveals the DAG structure in the program and allows ReStream to provide partitioned parallelism.
What’s most important is that ReStream never writes into the past of a multi-versioned state variable—it’s fine to create multiple parallel instances of all operators A, B, C, and D.
Individual instances of A need not coordinate amongst themselves and can process partitioned input in parallel.
What’s important is that no instance of B gets ahead of some instance of A in processing the input log.
That might cause writes into the past at the friendships multi-versioned state.
Similar relationships hold for other state variables.
ReStream implements a barrier mechanism to enforce the invariants guaranteeing safe processing writes to multi-versioned state objects.
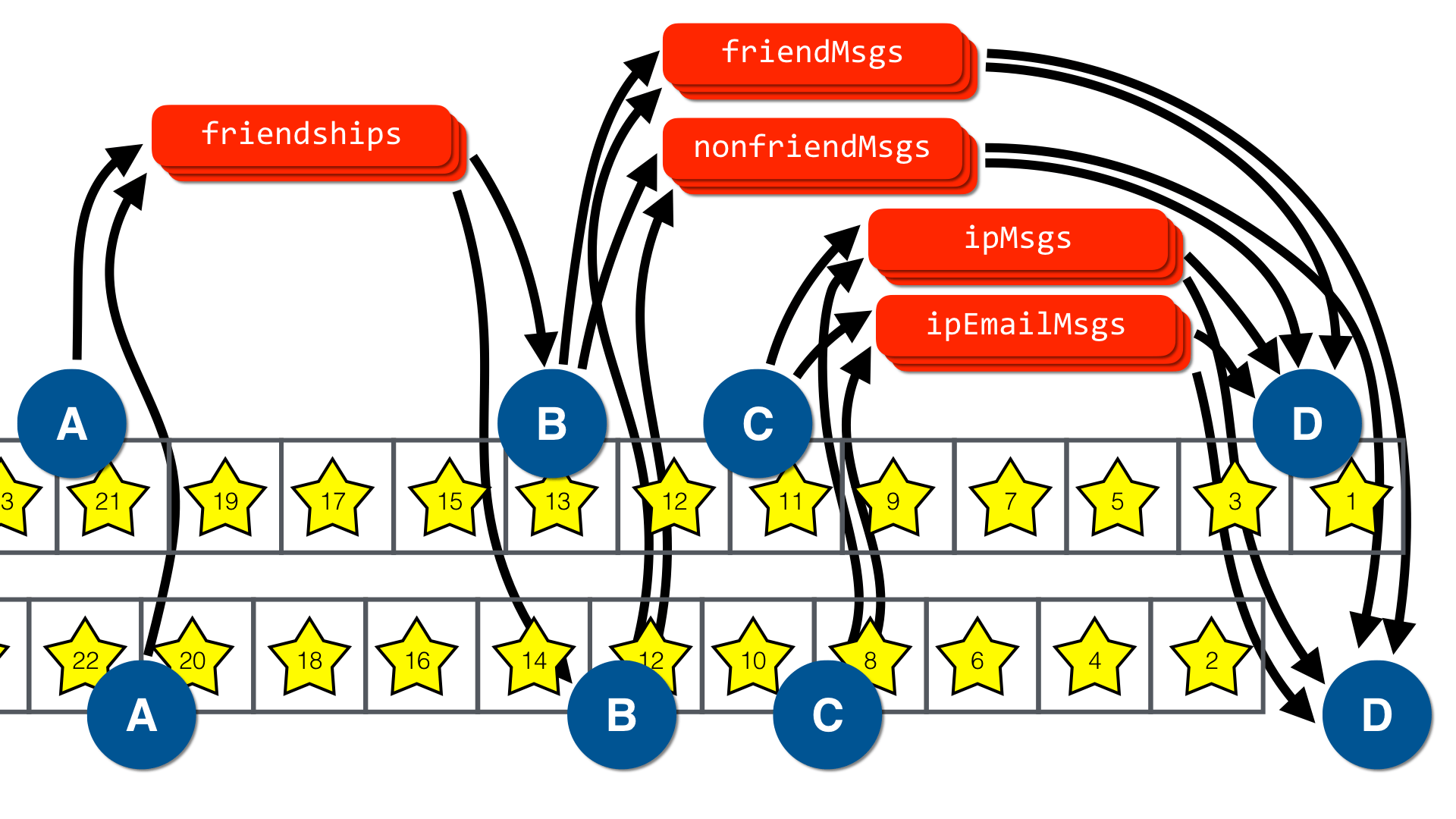
The diagram below illustrates ReStream in action with a partitioned log given as input. There are two copies of each operator, one of which receives odd-numbered events and the other of which received even-numbered events. So long as events flow to operators in accordance with the computation’s DAG structure multi-versioned state ensures serial-equivalent results.
Architecture
The ReStream architecture looks similar to many other systems with distributed parallelism.
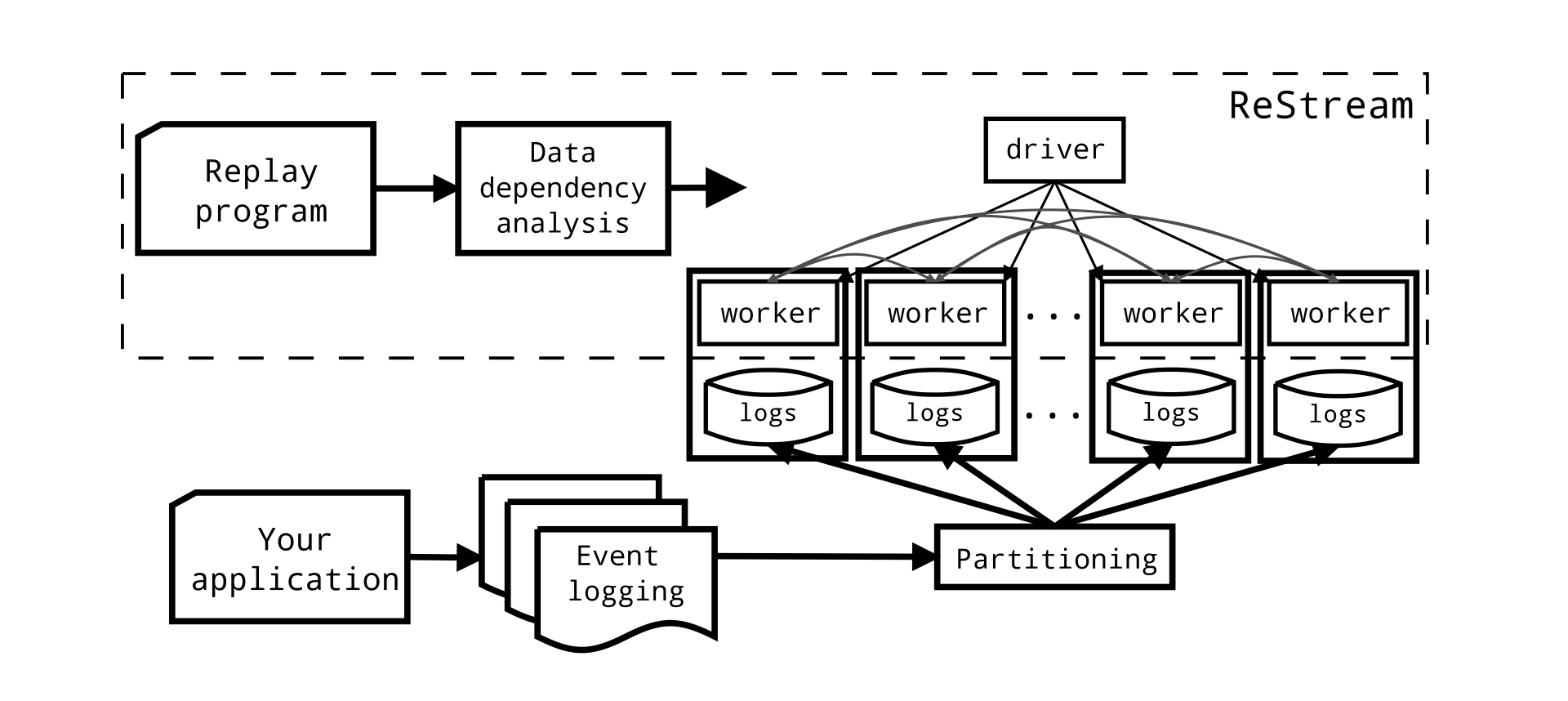
A centralized driver program collects progress from operators on each node and adjusts barriers as they advance. Multi-versioned state objects are distributed across worker nodes, but are globally accessible via reads and writes originating at any node. Each worker also receives a portion of the log. Note that no special input partitioning is required, we can distribute log entries arbitrarily. We do, however, require ordering within each partition as well as a global total order (i.e., a global log sequence number).
ReStream uses mini-batches to help amortize various overheads. These include the cost of coordinating progress at the driver program, as well as the latencies of reads and writes to multi-versioned state.
Evaluation and limits to scalability
ReStream shows good scalability as the number of machines grows, with throughput increasing by roughly 70% for each hardware doubling. Importantly, ReStream quickly outperforms an efficient single-threaded replay implementation, readily justifying the overheads of distributed computation and of maintaining multi-versioned state.
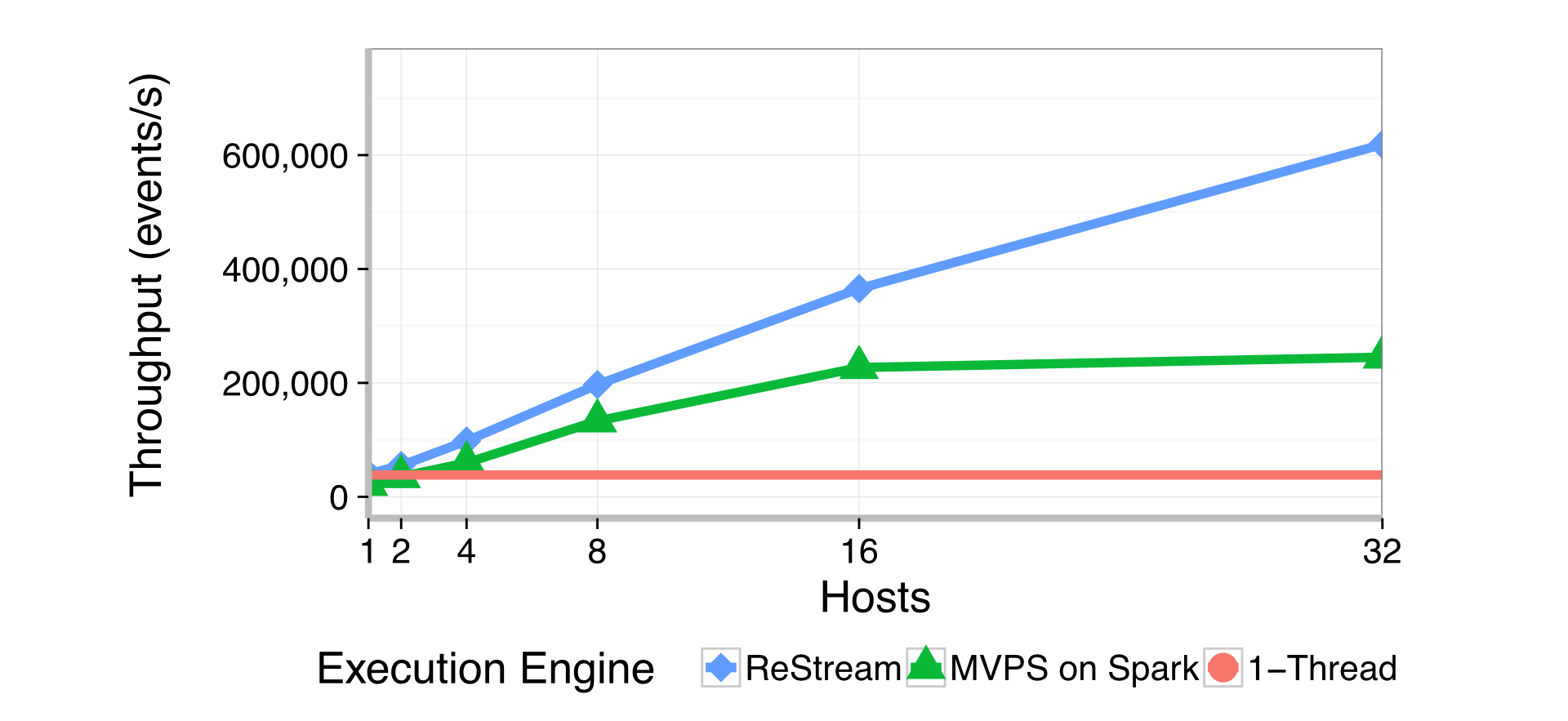
What limits ReStream’s scalability? We often think about the parallelism inherent in a program, but for data-driven applications the input matters as well. It is the interplay of input data and program execution that generates reads and writes to shared state, and it is these reads and writes that represent the causal dependencies that limit parallelism.
The graph below shows the throughput of ReStream running an anti-spam task on synthetic social network data. The power law scale parameter α describes the degree distribution of activity on the network, which varies across a range of practically relevant values. As activity becomes more concentrated around fewer users, as might be the case with celebrities on Twitter, ReStream’s ability to provide parallelism diminishes.
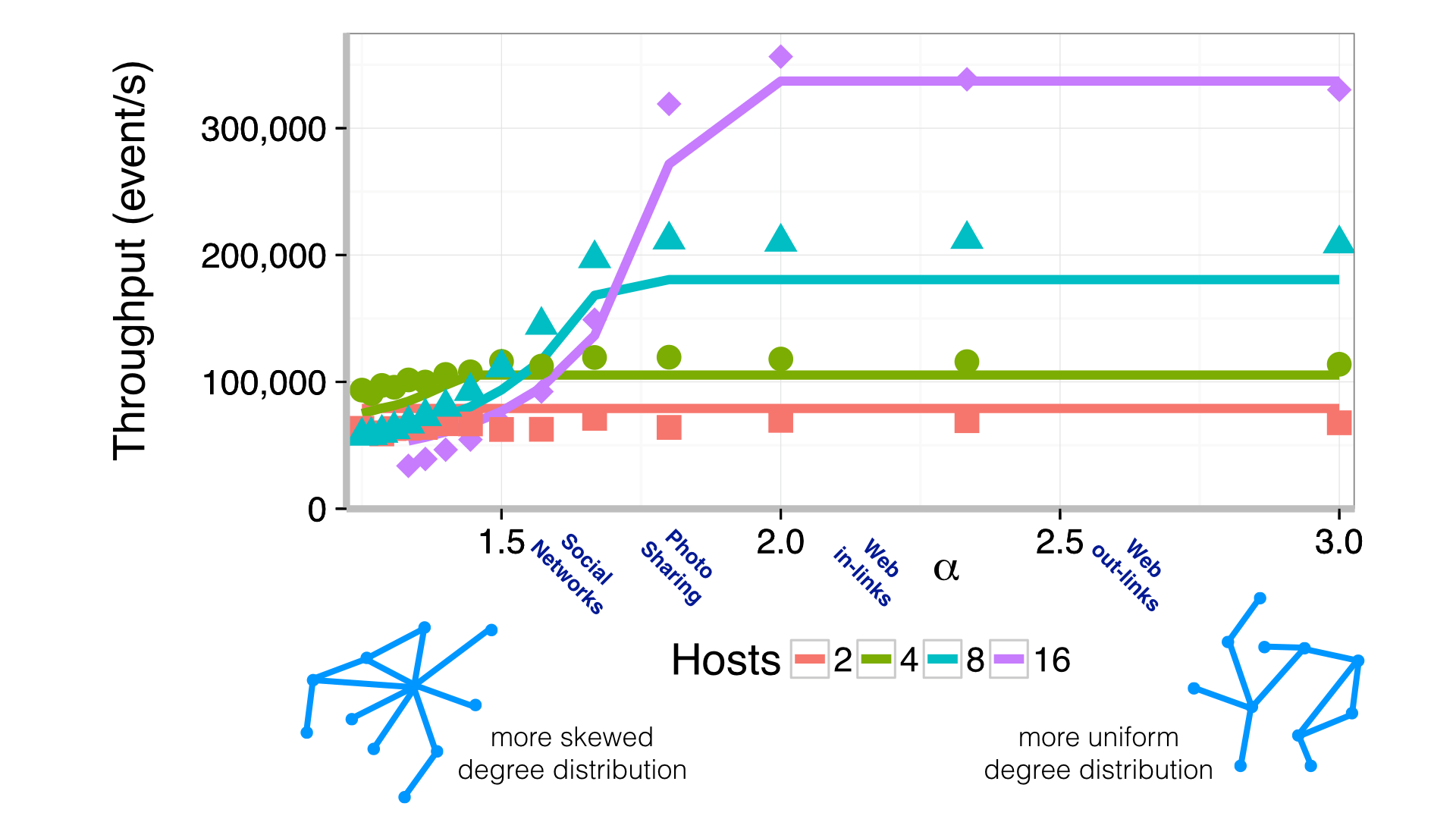
The solid lines represent a simple but effective model for ReStream’s throughput given by the formula below.
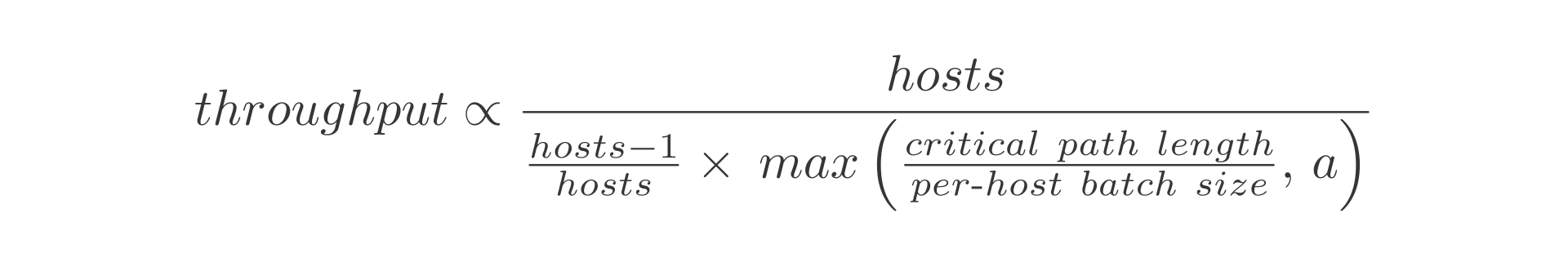
Here the term (hosts-1)/hosts models the cost of non-local communication. A specially instrumented version of ReStream logs all reads and writes to multi-versioned state. This model shows that when the critical path length through read-write dependencies exceeds a multiple of the per-host batch size, gains to performance are limited. This is represented by the term max(critical path length / per-host batch size, a). The model fits the measurements with a=1.85 and a quality of fit R2=0.94 across the range of per-host batch sizes from 2,500 to 40,000.
Summary
ReStream introduces Multi-Versioned Parallel Streaming (MVPS), a way of maintaining causal consistency with loose coupling. MVPS enables serial-equivalent parallel replay, a key need for backtesting of real-time applications, which can demand processing months of logs in hours or even minutes.
The traditional goal in stream processing is low latency. To my knowledge, ReStream is the first streaming system developed with the principal aim of high throughput. The capability for much-faster-than-real-time streaming can also be used to generate fine-grained training data for machine learning applications, or in scaling online stream processing.
The present implementation of ReStream is a research prototype. I invite anyone interested in building a production-ready MVPS implementation to contact me.
This work was supported in part by AWS Cloud Credits for Research.