It’s been a over year since I wrote here about Agile machine learning, work presented at KDD 2015 and based on my experiences at if(we). Looking back with the benefit of a bit of distance and looking ahead to problems of coming years, I’m compelled to comment on one aspect of the work that seems particularly relevant to the needs of future applications: the event history data architecture.
One of the keys to success in creating quick development cycles in machine learning is changing how we think about state. It may be most natural and common to update our databases and services to reflect the current “now” state of the world. This representation is important for real-time systems, which need to produce results in a fraction of a second using the most current facts available, but it poses other challenges. Training and backtesting models requires a sort of “what if” scenario analysis, one that uses historical data in new and different ways. Most update-oriented approaches to state require separate tracking or perhaps snapshots to reconstruct past versions of their state. Even then, supporting new features may be challenging.
A better approach is to log events or facts as they happen, then to compute any other necessary state by processing this log.
There’s not much to the basic Event interface:
interface Event {
timestamp: Long
}
One can think of this as a reductionist approach—just write down everything that happens, as it happens, and you’re guaranteed to be able to compute anything you might fancy in the future. A shared log is the central element of the event history architecture.
The following figure shows how both production development systems can draw from the same log, the content of the Event History Repository.
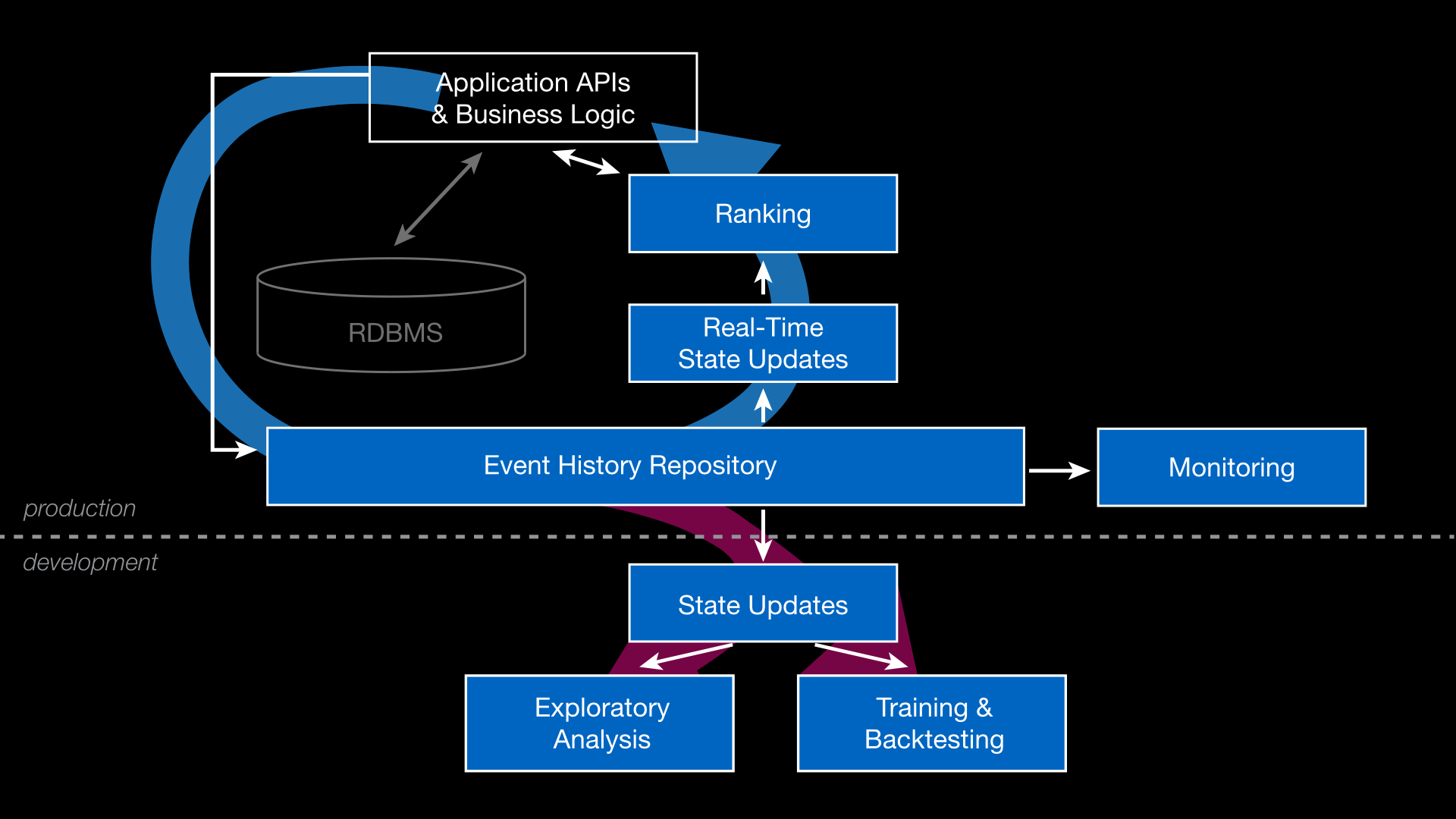
The same code can run in the the production environment Real-Time State Updates and in the development environment State Updates boxes. In production, state updates occur in services that power the live system, providing input for ranking and recommendations, or just simply data for display. In development, state updates occur in a simulation context, making it possible to revisit past events to generate inputs for training or evaluating models. The same approach also can be used to generate reports for inspection by developers or analysts.
The key to this unification is the simple Event History API:
interface EventHistory {
def publishEvent(e: Event)
def getEvents(
startTime: Date,
endTime: Date,
eventFilter: EventFilter,
eventHandler: EventHandler)
}
The second method, when called with a finite end-time, is suitable for revisiting activity from a past time period. When called with +∞ as end-time, it streams data to the event handler, which is just what is needed for real-time production deployments.
A few months ago Netflix published a detailed blog post describing Distributed Time Travel for Feature Generation. They highlight the value of real-time recommendations and list a concise set of requirements for developing the necessary models. Among these, they desire a system that “accurately represents input data for a model at a point in time to simulate online use.” Netflix developed an robust mechanism for recording snapshots of state from across the numerous services that provide input to their recommendations. As an upgrade to established infrastructure their solution makes sense, but an event history architecture could be a good future direction.
Implementing an event history architecture today is challenging because platform support for the API is limited. However, there are some technologies that can show us the way:
- Event Store - perhaps the only database designed from the ground up to ingest state as a series of events. Its lead developer is Greg Young, who has been a proponent event processing as a central application abstraction.
- Confluent - a commercial extension of Apache Kafka. Kafka was created by Jay Kreps, author of The Log: What every software engineer should know about real-time data’s unifying abstraction, one of my favorite blog posts.
- Antelope Realtime Events - my demo implementation of tools for feature engineering and for building real-time recommendations using an event history API. This is based on work done at if(we). It is not a production implementation and I am no longer developing it.
I would be thrilled to see a really robust and practical implementation of an event history database. One can build this today by combining existing streaming and data storage (e.g., Kafka + HDFS), but a purpose-built system would be better still, one that implements the event history API directly.
There’s also plenty of room for interesting research. For example, I’m sure we can learn a lot from trying to apply event history in the context of a various different of machine learning techniques, including deep learning. Another intriguing problem is how to take a log and roll it forward quickly and efficiently, either generating intermediates or to jumping ahead to the present, as when creating a new view of history. I have done some work in this area recently, which only convinces me more that this will be a fruitful direction.
The production needs of real-time machine learning systems call for a streaming, incremental, event-based approach to processing data. Capturing these events in a log and replaying them brings twin benefits: allowing shared code between production and development and providing a time-travel capability. The event history API provides a unified point of access to streaming events, both real-time and historical, and deserves to serve as the foundation for modern data-driven intelligent systems.
I’d love to hear about it if you’ve implemented this approach or if you’re considering something similar.
Related reading:
- Kappa Architecture - all data is represented as an append-only log and all data processing is stream processing.
- Event Sourcing and CQRS - design patterns known in the world of Microsoft / C#. Applications are built on top of a log-oriented data store rather than a mutable state abstraction.