This post outlines the motivation for the paper I am presenting at KDD this year, An Architecture for Agile Machine Learning in Real-Time Applications.
2 weeks « 6 months
Why is deploying applications based on machine learning often so slow? That’s the question we asked ourselves at if(we) following yet another 3-month cycle of product development, one that ended up showing small improvements, but one that left us questioning whether the whole effort was worthwhile.
We had a strong team, talented data scientists and talented programmers, a team with ample and relevant experience earned at well-known companies and famous universities. We were good at building software, but the complex software development required to deploy simple trained systems seemed grossly incommensurate to the relative simplicity of our models.
We wanted to iterate rapidly, to go quickly from ideas for new personalized recommendations to trained models, to production experiments, to results that would test those ideas. In practice, model deployment presented tremendous obstacles in what otherwise promised to be a powerful innovation cycle:
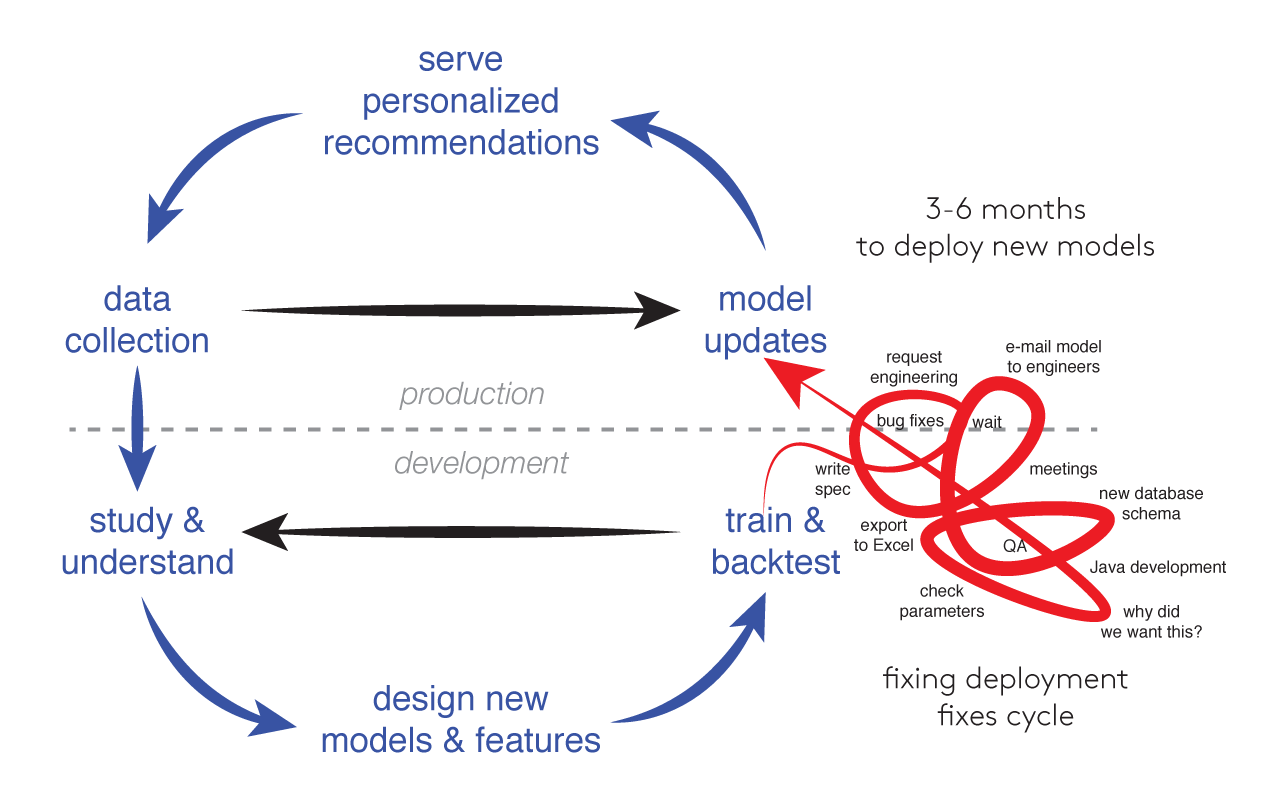
In many ways, these experiences reminded us of many of the problems that successful consumer internet developers had left behind a decade ago. Whereas we had gotten good at shipping simple A/B experiments quickly, often building enhancements in just a few days and using our million-user scale to take statistically sound measurements just a quickly, our experience with machine learning stood in stark contrast, with daily releases replaced by 3- to 6-month software projects. In some cases, we failed entirely, never managing to reach the requirements of scale and performance demanded by our environment, even after data scientists had demonstrated offline predictive algorithms that promised to improve the user experience.
There were our needs:
- Product cycles measured in days not months
- Scale to >10 million recommendation candidates
- Responsiveness to current activity (updates within 10 seconds)
- Instant query results for users (less than 1 second)
The platform we developed in response to these requirements routinely allows us to go from new ideas to results validated in production experiments in just two weeks. Fixing the model deployment step allowed us to fix the Agile development cycle for machine learning applications.
Data makes it different
Why don’t traditional Agile software development practices translate to machine learning products? What makes such applications uniquely challenging to deploy? Well, to a large extent, they do translate. Version control, continuous integration, project planning methodologies, and more, all can help in straightforward ways.
The key difference in machine learning is the central role of data. Even a very simple feature, say one that incorporates product popularity into rankings, needs to both draw upon both data collected before deployment as well as to incorporate future information as it becomes available. Disparate paths to data, one for the past and one for the future, introduce additional complexity, often at to an extent that greatly exceeds that inherent in the product’s functionality.
The key to alleviating deployment challenges is to provide a single path to data, one that puts past and future data behind the same abstraction, and one that is equally practical in a production setting as it is at a data scientist’s desk.
Our experience
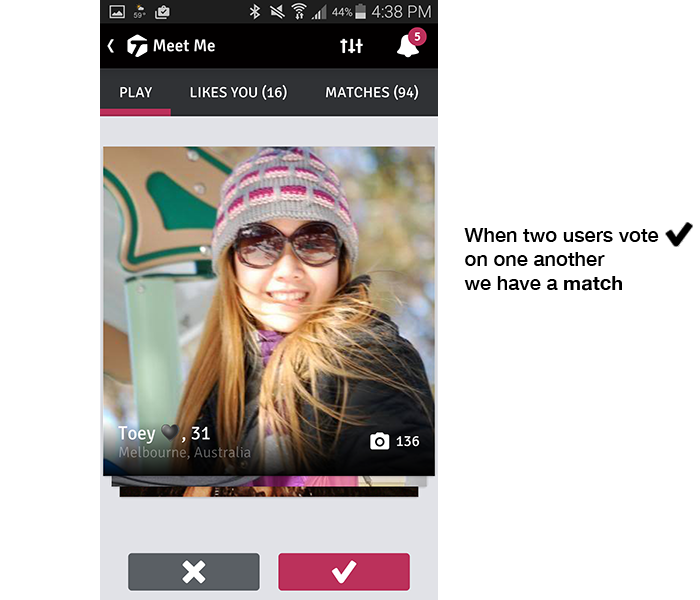
Meet Me is the primary dating feature of the social platform powering hi5 and Tagged. The interface shows one profile at a time, allowing users to tap or swipe, voting yes or no to indicate their interest in connecting. When the attraction is mutual, when both users vote yes on one another, we call this a match and conversation can ensue. Below is a screenshot of the Tagged Android application.
Past social interactions are a potent predictor of future interactions, so using machine learning techniques was a natural evolution after heuristic attempts to improve matching showed diminishing returns.
After experiencing deployment challenges as a consequence of disparate paths to data, we re-architected our predictive platform using a design that we call “event history architecture.” In this approach, the only route to data is through a time-ordered event history that exposes a simple interface:
interface EventHistory {
def publishEvent(e: Event)
def getEvents(
startTime: Date,
endTime: Date,
eventFilter: EventFilter,
eventHandler: EventHandler)
}
Setting endTime to +∞ in the EventHistory interface results in real-time streaming, so the interface provides access to both historical and future data in one call to getEvents.
Since raw events are not suitable input for our machine learning algorithms, we invest in a feature engineering language that makes it easy to transform an event history into meaningful measures of user interaction. For example, a simple feature might maintain statistics on the ratio of yes to no votes for a particular user, perhaps broken down by according to age ranges, a reflection of the individual’s preferences. Our environment allows a great deal of flexibility in such transformations.
With model features derived from event history, we directly deploy to production the same feature engineering code used by data scientists in development. The cycle of software development that used to intercede between a model training and production deployment is now replaced with a few simple steps:
- Deploy feature engineering code (identical to code used during development)
- Deploy model parameters obtained training
- Hit go: replay history with new feature engineering code, continue with real-time updates once system catches up to present.
Our paper describes our system in detail, and the Antelope open source project includes examples drawn directly from our experience. The dramatic impact on our business is shown by the usage metrics:
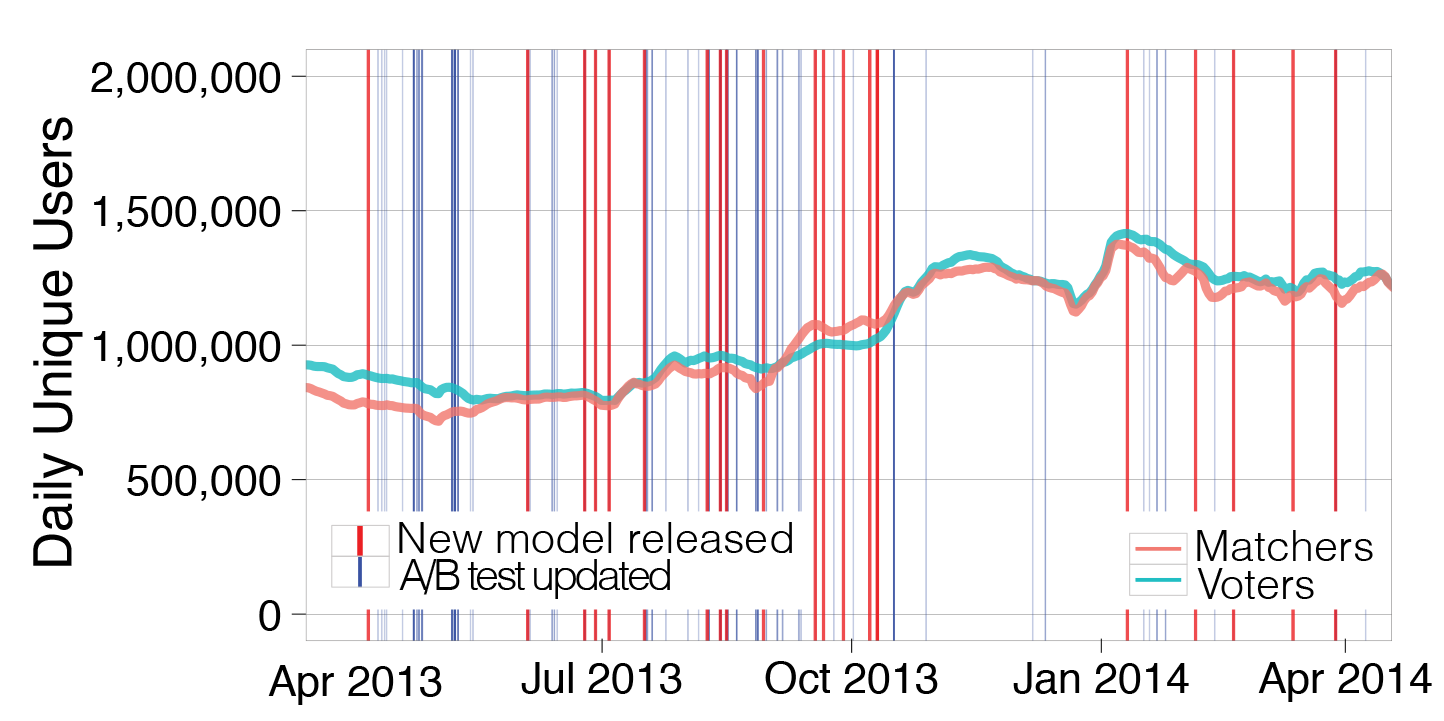
During an especially intense 6-month period of iterative product development we released 15 new models, updating experiment parameters 123 times along the way. Results from A/B testing showed a cumulative increase in daily users of Meet Me exceeding 30%.
The Agile advantage
Achieving rapid product cycles allows data scientist to stay focused. They can immediately evaluate how users respond to new recommendation algorithms, then use the understanding gained in further feature engineering. Teamwork also improves, as models readily deployable to production are just as readily deployable to colleague’s development environment.
For us the contrast could not be more stark: going from 6-months spent working on one model implementation, only to achieve unimpressive gains, to releasing a string of improvements over a similar time period, each building on the other and cumulatively delivering substantial improvements in both user experience and key business metrics.
In most machine learning applications, there remains a tremendous gulf between demonstrations of what is possible and the constraints of what is practical in an industry setting. Building systems based on a single path to data, building model features from an Event History API, allows rapid deployment cycles and dramatically accelerated progress.